| プロセルピナ | ||||||||||
| Top |
Internet |
Private Proxy |
Capture Device |
Download |
Config and Words |
Online Help |
Online Home |
|||
| [BACK] | |||||||||||
☞
Top >
Mail >
Filtering >
Bayesian >
F5
F5 キーを押すだけで、 View部メインフォームで表示中のメールに対し ベイジアンフィルタ(Bayesian Filter)によるジャンクメール判定を行うことができます。
F5 キーによる機能では 判定結果を表示するだけで、 メールの移動や廃棄などは行いません。 利用例:辞書の成長確認にベイジアンフィルタで使用するBayesian辞書(=確率テーブル)が 実用的なレベルにまで「成長」したかどうかを確認する目的で使用することができます。 通常メールとジャンクメールの幾つかに対して[F5]キーで判定を行い、 正しく判定されているようならメールフィルタにベイジアンによる判定を組み込みます。 → Bayesianコマンド (メールフィルタコマンド) 利用例:判定結果の詳細なチェックにメールフィルタに組み込んだベイジアンフィルタで誤判定されていたメールに対し、 [F5]キーで 個別に判定を行ってその詳細を表示することにより ベイジアンフィルタの動作確認を行います。 誤判定されたメールはベイジアンフィルタに学習させます。 → ベイジアン辞書にメールを学習させる ベイジアンフィルタの学習例次の図のFig.1は、ジャンクメールを対象に F5 キーで ベイジアンフィルタによる判定を行った場合の表示例です。  Fig.1: ベイジアンフィルタによる判定 (学習前) f値が1に近づくほど ジャンクメールに近いと判定されます。 「プロセルピナ」ではf値が 0.900 を超えるメールをジャンクメールと判定しています。 上記のFig.1の例では メール全体のf値が0.010 となっていて、 使用しているBayesian辞書の学習が不足しているのかジャンクメールと判定されていません。 結果を詳細に見ると、個々の単語ではf値が高いものがありますが、 通常メールに含まれていた単語(f値が低い)も多く含まれていて それが全体のf値を下げています。 例えば、このメールに含まれていた「恋愛」という単語は ジャンクメールとして登録されたメールに875件も含まれていた一方、 このユーザの通常メールには2件しか含まれていなかったので、 f値は0.999と高いものになっています。 しかしその一方で「イベント」という単語はジャンクメールに368件含まれていますが、 通常メールにも254件含まれているので、 f値は0.054と低いものになっています。 (ジャンクメールと誤判定される危険性を下げる為、ベイジアンの計算式では ジャンクメールと通常メールとで 同じ程度にに含まれる単語のf値は 中間値0.500に比べても かなり低くなります) ここで、このメールをジャンクメールとして学習させます。 → ジャンクメールとして学習させる 学習後、再び [F5]キーでベイジアンフィルタによる判定を行ったのが 次のFig.2の例です。 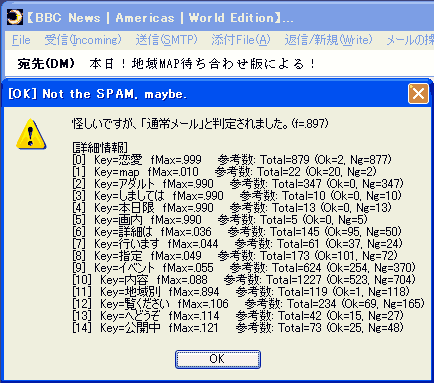 Fig.2: ベイジアンフィルタによる判定 (学習後) f値が 僅かに0.900を超えなかったので 結果としてジャンクメールとは判定されていませんが、 「学習」によって確実にf値が上昇している(0.010→0.897) ことが確認できます。 この後に 類似の内容のジャンクメールが届いた場合に 再度学習させると、ほぼ確実にジャンクメールと判定されるでしょう。 ここでは学習の例として、再度同じメールを「学習」させることで 結果がどう変化するかを確認します。 (注:辞書の語彙の偏りを防ぐため、実際の運用では同じメールを繰り返して学習させないようにします) 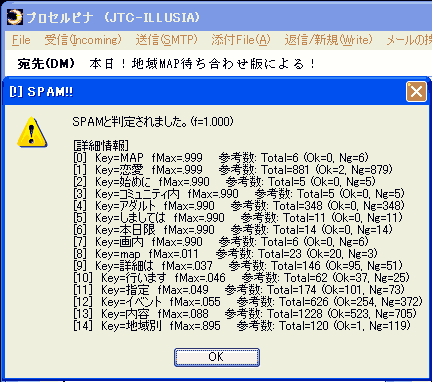 Fig.3: ベイジアンフィルタによる判定 (再学習後) 今度はジャンクメールと判定されました。 以降は類似した内容(=類似した語彙が使用されている内容)のメールはジャンクメールと判定されます。 ジャンクメールのURLジャンクメールにはアクセス先のURLが記載されていることが殆どですが、 これももちろん 単語に分解されてBayesian辞書に登録されます。 「プロセルピナ」のベイジアンフィルタで実装している単語解析処理では URL解析用の特殊処理が追加してあり、 メールに記載されたURLからホスト名の部分を抽出し、 それをBayesian辞書に 普通の単語登録に加えて登録します。 ジャンクメールが誘導しようとした先のURLが変化していたとしても ホスト名までは変化しないことが多く、 このホスト名抽出処理によって 少ないジャンクメールの登録でも ジャンクの判定が高確率で行えるようになります。 以下の例では、全て「example.net」というホスト名がBayesian辞書に登録されます。 (1) http://www.example.net/lovelove.cgi (2) http://www3.example.net/yourprofit/getitnow.cgi (3) http://kissme.www.example.net/goodforyou/bigmoney.php?yourName ジャンクメールのURLに記載されたホスト名は 通常メールにはまず含まれることのないホストですから、少ない回数しか出現しない場合でも 自動的にf値が非常に高い単語として登録されます。 例えば学習させたメールには たった5回しか出現しなかったホスト名だったとしても、 それが通常メールには全く含まれないホスト名の場合なら、単語のf値は 0.990 といった非常に高いものになります。 メールの振り分けにおいて、URLに記載されているホスト名は ジャンクメールを抽出する良いキーワードになります。 |
|||||||||||
| [BACK] | |||||||||||
| プロセルピナ | |||||||||||
